

This is my last week on my current job, and I was reflecting about some of the things that I've learned in the past 7 years there. There's a lot of course! As a staff data engineer, I worked with many teams and codebases and learned a couple of tricks at scale. So I'm starting a new blog series "performance advice nugget" (or PAN for short), in which I'll share some insights of what worked quite well in practice.
So welcome to PAN 01: use flat representations.
I'll try to make these posts quite short. As usual with everything related to "performance", you should always measure and benchmark with your real workload, and always balance whether additional complexity is worth the performance gains.
Nice, forewords are said and out of the way. Let's focus on the matter: imagine that you are handling a data that has multiple levels, for example, a paragraph, that is made of sentences, each made of words, each made of characters:
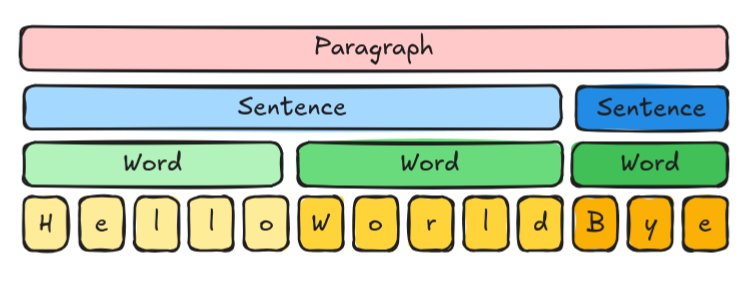
One straight way to model this is with lists of lists:
class Paragraph:
sentences: list[Sentence]
class Sentence:
words: list[Word]
class Word:
chars: list[str]
data = Paragraph([
Sentence([
Word(["H", "e", "l", "l", "o"]),
Word(["W", "o", "r", "l", "d"]),
]),
Sentence([
Word(["B", "y", "e"]),
]),
])
Note: don't overthink Word in this synthetic example! In a more realistic setup, Word could probably just be a
str. But here I'm using it to illustrate the "layered" modeling.
Today's PAN is: don't nest the lists! Instead, keep the leaf information (here the chars) flat in a single list. Then use other lists to index into the flat representation:
class FlatParagrah:
characters: list[str]
words: list[WordInfo]
sentences: list[SentenceInfo]
class WordInfo:
num_chars: int
class SentenceInfo:
num_chars: int
num_words: int
data = FlatParagrah(
characters=["H", "e", "l", "l", "o", "W", "o", "r", "l", "d", "B", "y", "e"],
words=[
WordInfo(5),
WordInfo(5),
WordInfo(3),
],
sentences=[
SentenceInfo(num_chars=10, num_words=2),
SentenceInfo(num_chars=3, num_words=1),
],
)
Why? Two main reasons:
- CPU caching: CPUs are more efficient when accessing data that is packed closer together
- less allocations: each list has to be allocated and deallocated individually. The flat design has a fixed and small number of lists
Is it true?
Well... as it's usual with data structures, it will highly depend on what you actually do with the data! In our case, it worked wonders.
I've prepared a micro benchmark in Rust to illustrate, you can check the source code for Paragraph and FlatParagraph.
| Operation | Paragraph | FlatParagraph | Gain |
|---|---|---|---|
| Create | 2100 ns | 370 ns | 5.7 x |
| Deallocate | 460 ns | 39 ns | 12 x |
| Iterate over words | 91 ns | 100 ns | 0.91 x |
| Iterate over chars | 110 ns | 32 ns | 3.4 x |
| Create with inserted word | 2400 ns | 350 ns | 6.9 x |
The last operation is the one that our codebase did the most: create a new Paragraph from an existing one by inserting a new word in the middle of it. Something like:
class Paragraph:
def with_inserted_word(
self,
paragraph_i: int,
word_i: int,
word: list[int],
) -> 'Paragraph':
pass
And we've used a lot Rust's type system to provide an ergonomic and safe API for the rest of the codebase to handle the data, allowing it to cut and slice the "paragraph" however necessary.