

In Rust, the tokio's ecosystem has a fundamental crate called bytes that abstracts
and helps dealing with bytes (you don't say!). I've indirectly used it a billion times and I thought that I had a good
mental model of how it worked.
So, in the spirit of the "decrusting" series by the excellent Jon Gjengset, I've decided to peek behind the curtains to understand more what axum, tokio, hyper and the kind do to them bytes! The code is well written, but surprisingly complex. I understand now what it does, but I still don't fully grasp why it does some things in a certain way.
I'm ready to share with you my discoveries. I hope that you are sitting, laying or squatting comfortably. This is the first post in a small series. I'm legally required by my marketing department to remind you that you can subscribe to my low-traffic newsletter, so that you'll know when new posts are up!
A quick note before we start: this posts is based on the current bytes version 1.11.1.
What the Bytes?
The bytes crate does many things, but its public API is quite small: it basically has two structs and two traits.
Quoting from the documentation:
struct Bytes: a cheaply cloneable and sliceable chunk of contiguous memorystruct BytesMut: a unique reference to a contiguous slice of memorytrait Buf: read bytes from a buffertrait BufMut: a trait for values that provide sequential write access to bytes
In this series, I'll focus on the Bytes struct, because yeah, it's not as simple as one may be led to believe!
A compelling example
I would like to start concrete, with an example of what the problem that Bytes helps solve: zero-copy parsing.
Imagine that you're parsing HTTP requests and your code receives these bytes from the network:
GET /post/2026/some-post HTTP/2 Host: sitegui.dev Accept: text/html Referer: https://sitegui.dev/ Connection: keep-alive
You would like to efficiently parse it into a struct like this:
struct Request {
method: Something,
path: Something,
version: Something,
/// Note: headers can repeat, so I'm using a
/// `Vec` not a `HashMap` to represent them
headers: Vec<(Something, Something)>,
}
This post is not about the parsing bit, instead it's about the bytes themselves. What should we choose as Something
above?
If you chose a type like Vec<u8>, your parser would need to allocate and copy the information into many
multiple instances of Vec<u8>. But with Bytes, all these instances are cheap to produce as they share the same
storage (your initial bytes are represented only once) and each instance then has a "window" to
this buffer. The underlying buffer will only be deallocated when all the instances sharing it are dropped.
As usual in computing, using Bytes (or any "shared" construction) vs Vec<u8> (or any "owned"
construction) is a matter of trade-offs. For example, if your parser code only produces output that references a
small part of the input, it's probably better to copy over just that. Otherwise, the Bytes instances will keep the
whole input around in memory.
An initial mental model
As I said before, I had a useful mental model before embarking in this exploration: a Bytes instance simply has a
reference-counted shared reference to the actual bytes and some information to where in the buffer those bytes are.
The fundamental operations available are:
trait BytesStorage {
/// Create a new instance with some data
/// It should "adopt" the data, not copy it
fn new(data: Vec<u8>) -> Self;
/// Create a new instance that references some part of this data
/// Constant time, and it should not copy the actual data
fn slice(&self, range: Range<usize>) -> Self;
/// Return the bytes slice
/// Very cheap
fn as_ref(&self) -> &[u8];
}
We could draft a similar-in-spirit implementation using Arc<Vec<u8>>:
pub struct SharedBytes {
range: Range<usize>,
data: Arc<Vec<u8>>,
}
impl BytesStorage for SharedBytes {
fn new(data: Vec<u8>) -> Self {
Self {
range: 0..data.len(),
data: Arc::new(data),
}
}
fn slice(&self, range: Range<usize>) -> Self {
// Translate the "local" range to a "global" range
let root_range = range.start + self.range.start..range.end + self.range.start;
Self {
range: root_range,
data: self.data.clone(),
}
}
fn as_ref(&self) -> &[u8] {
&self.data[self.range.clone()]
}
}
Note how new() does not clone the data, instead the Vec is adopted into the SharedBytes instance.
Also, slice() clones the Arc<_>, which uses reference counting and avoids cloning the actual data in the Vec.
However, as_ref() is not very good for two reasons: Rust will execute bound checks to ensure that the range is valid
at every access, and the actual buffer is behind two memory references Arc (in SharedBytes) -> Vec -> buffer.
The actual Bytes implementation avoids these two problems by storing the slice components (pointer to first byte and
length) as two fields directly in the struct, trading off some bloat in the struct and a small performance hit in the
slice() operation for a simpler as_slice():
pub struct Bytes {
ptr: *const u8,
len: usize,
// ... more fields ...
}
impl Bytes {
#[inline]
fn as_slice(&self) -> &[u8] {
unsafe { slice::from_raw_parts(self.ptr, self.len) }
}
}
Let's test our mental model
In Rust, you can set a different global memory allocator like this:
use std::alloc::{GlobalAlloc, Layout, System};
/// A global allocator that can track all allocations made
struct TrackingAllocator;
// Ask Rust to use our allocator as the global allocator
#[global_allocator]
static ALLOCATOR: TrackingAllocator = TrackingAllocator;
unsafe impl GlobalAlloc for TrackingAllocator {
unsafe fn alloc(&self, layout: Layout) -> *mut u8 {
// Do stuff
unsafe { System.alloc(layout) }
}
unsafe fn dealloc(&self, ptr: *mut u8, layout: Layout) {
// Do stuff
unsafe { System.dealloc(ptr, layout) };
}
}
There is a Rust working group to have a more fine control of the allocator, allowing us to overwrite it only for some parts of the code. But for this reduced example, it's okay to capture all allocations.
I used this mechanism to track exactly which allocations and deallocations the code was doing for Vec<u8>, our own
SharedBytes and bytes::Bytes and where in the source code they
happened. You can check the full code here,
if you are curious or want to reproduce my work.
To simulate the HTTP parser, I'm using this simple code:
fn parse_request<B: BytesStorage>(data: Vec<u8>) -> Request<B> {
let data = B::new(data);
Request {
method: data.slice(0..3),
path: data.slice(4..24),
version: data.slice(25..31),
headers: vec![
(data.slice(33..37), data.slice(39..50)),
(data.slice(52..58), data.slice(60..69)),
(data.slice(71..78), data.slice(80..100)),
(data.slice(102..112), data.slice(114..124)),
],
}
}
The following table shows what each line of the code above allocates for Vec<u8>, SharedBytes and bytes::Bytes, in
bytes.
But before looking at the results, take a while to run this code against your mental model and try to predict how many allocations will occur for each implementation and where that will happen.
| Code source | Vec<u8> |
SharedBytes |
bytes::Bytes |
|---|---|---|---|
data = B::new(data) |
40 | ||
method: data.slice(0..3) |
3 | 24 | |
path: data.slice(4..24) |
20 | ||
version: data.slice(25..31) |
6 | ||
vec![...] |
192 | 192 | 256 |
8x data.slice(...) |
57 | ||
| Total | 298 | 232 | 280 |
As I expected, Vec<u8> allocates a new independent buffer in every call to .slice(), with the necessary capacity for
the data piece then copy it. SharedBytes allocates the Arc<Vec<u8>> once at the start, and later the
Vec<(B, B)> with 8
× 24 bytes.
I want to explore in a separate blog post the whys and the hows Arc<Vec<u8>> has 40 bytes, and also compare it
against Arc<[u8]>. Stay
tuned!
The behavior of Bytes was interesting to me for two reasons:
- it somehow defers the first allocation:
B::new()doesn't allocate (in this case), but the first call to.slice()does. Spoiler alert: it's pretty neat but complex. I'll explore it in details later on. - it's big! 32 bytes each instance. So
Vec<(B, B)>has 8 × 32 bytes
No Arc in sight
Armed with the above initial mental model, it's not a surprise that the documentation and comments in the file
implementing Bytes mention Arc 6 times. What is a bit eyebrow-raising is that the code itself does not use Arc
at all!
Maybe it's related to the defered allocation we saw before? Maybe it's related to the 32 bytes needed for each instance? Well, kind of...
I'll use memory diagrams like this one below to represent what the structs (in grey) are made of. Simple numerical fields are in yellow and pointers are in green. In parentheses, I've put the memory size in bytes, assuming a 64-bit system.
For example, in Rust you can represent a growable owned sequence with Vec<T> and a fixed owned sequence
with Box<[T]>. The physical difference is that Vec may have allocated more space than it is currently using, to
amortize buffer grow on inserts, so it uses an additional capacity field. A Box uses exactly the bufffer's size, so
length and capacity are the same. Converting from a Vec that is "full" (that is, for which capacity is the same as
length) is cheap because the underlying buffer is reused:
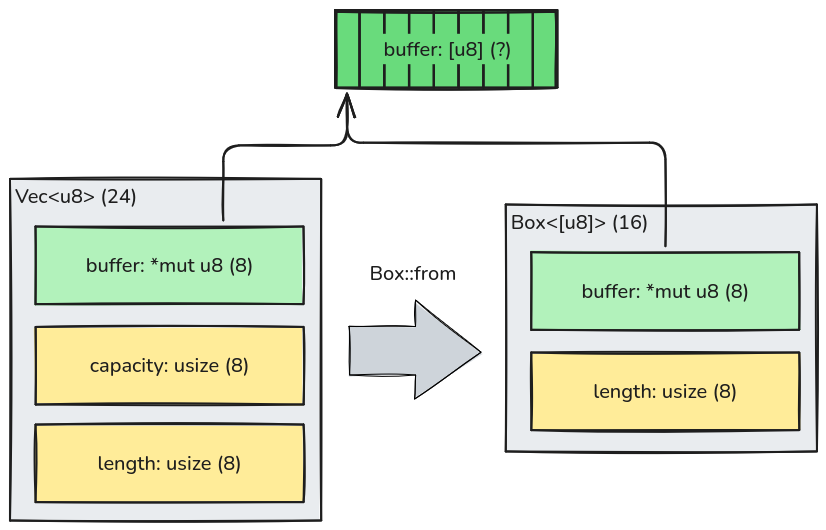
Here's a Box. Give-me Bytes
The implementation of Bytes::from(Vec<u8>) will first check if it's a "full" Vec to convert it into a
Box<[u8]> and build a Bytes instance like below. When the Vec<u8> it not "full", a different logic is used, but
let's
put that aside for now.
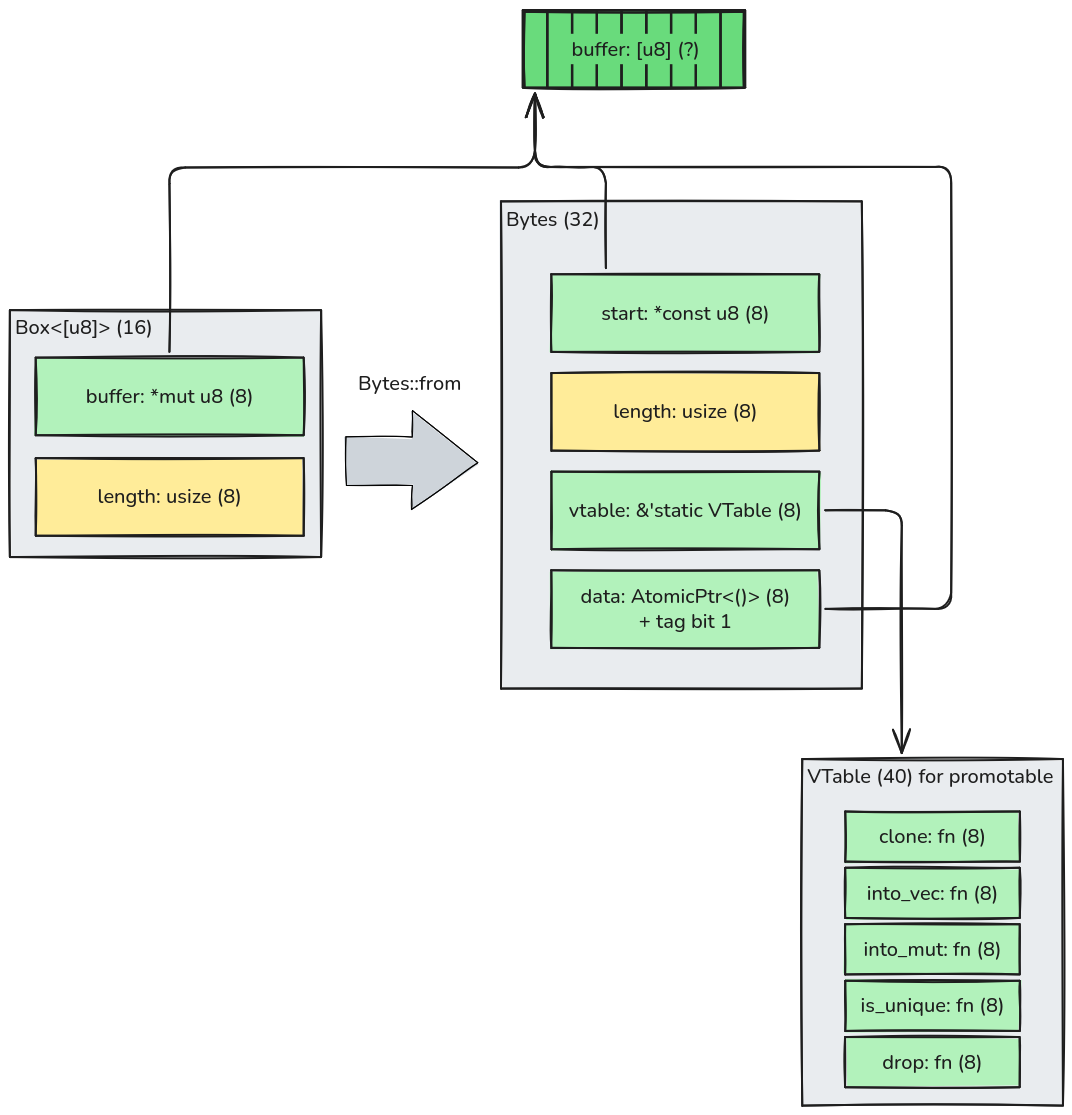
That's a lot to unpack. I'll explain what I've understood of the design and the trade-offs of this representation:
First, note that the buffer is reused, as expected.
The start and length fields simply represent the slice information. It seems a bit redundant with the data
field, that also points to the buffer. However, this distinction will be useful when we slice this data: the start
of our "window" will be different from the buffer's start, and we need to keep the buffer's start around so that we
can deallocate it when the moment comes.
The vtable field implements the "dynamic dispatch" pattern. Rust has "trait objects" to implement this pattern with
&dyn SomeTrait or Box<dyn SomeTrait>, but I guess the designers of the crate didn't use them because this pattern
has restrictions that are a deal-breaker for this use. If you know more why, please tell me!
Note that vtable points to a statically declared instance of VTable called "promotable". Aha! This name is related
to how Bytes deferr allocation as we observed earlier.
The data field is funny-looking (no judgements!): it's an AtomicPtr<_>, that unlike a normal pointer, uses atomic
operations to read/write to it. But why do we need atomic operations here? Spoiler alert: it's the deferred allocation
again. Somehow (we'll see next), this pointer will point to something else in the future.
Continuing on the data field, it's not just a pointer. It uses the pattern of "tagged pointer" to store one bit of
information there. I think you can already guess it: it's the deferred allocation again. This trick avoids having a
separate field for this, but it requires the code to ensure and check that the pointer to the buffer is always a
multiple of 2, so that the least bit carries no useful information and can be co-opted as a tag.
The other side of the river
Let's spring straight into action: what happens when we slice our newly-created Bytes? I've tried my best to
convey everything that happens in the diagram below without making it too busy. Take some time to navigate it first.
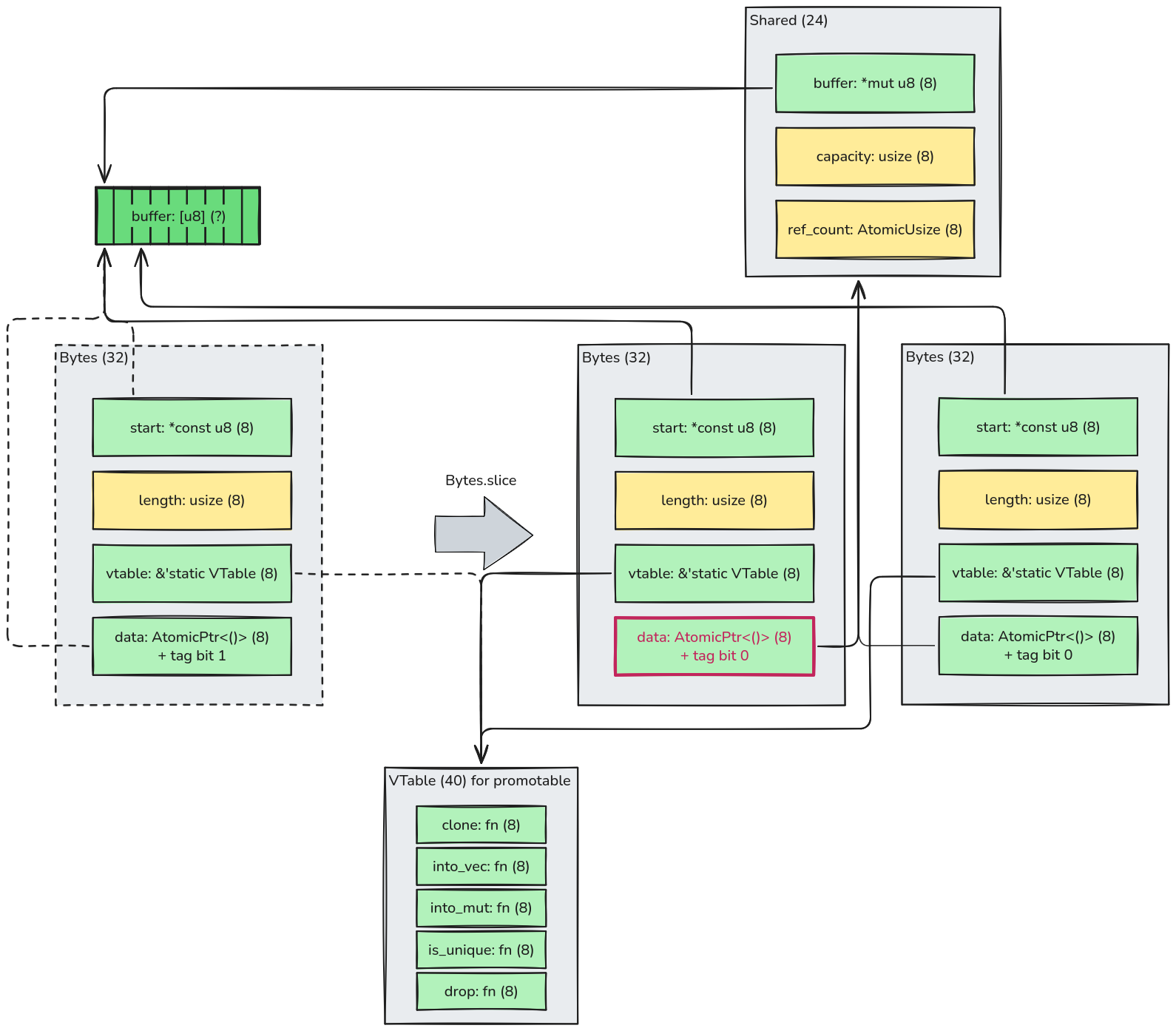
First, note that calling .slice(&self) the first time actually modifies the original Bytes: the previous state of
the instance is represented in a dashed countour, the new state uses red on the changed field: data. Naturally, only
this field can be modified, because .slice(&self) takes a shared reference, so only internal mutation is possible,
through the
AtomicPtr<_>.
As we've observed earlier, a new piece of data is allocated: an instance of the Shared struct with 24 bytes. It
carries information about the original buffer that will be used to deallocate (buffer and capacity). I was surprised
to learn that in Rust the original size of the buffer is actually necessary to deallocate it. I was used to C's
free(ptr) that clearly doesn't need it.
The Shared struct also carries an atomic counter with the number of Bytes instances referencing this buffer. The
implementation doesn't use Rust's native Arc. Instead the designers preferred re-implementing it. I could not find a
definitive answer to why, but I guess that's because they wanted to avoid the overhead in Arc related to the
implementation of "weak references", that is not necessary for Bytes' use case. To implement it, Arc uses an
additional atomic counter and executes some extra atomic instructions when cloning and droping.
Finally, note how the vtable pointer does not change: it's still the same "promotable" method list. The code uses the
tag in the data pointer to distinguish a not-yet-promoted data (tag = 1) from a promoted data (tag = 0).
The deferred allocation feature is a trade-off: the code is more complex because we need an AtomicPtr and a tag to
implement it. However, for code that creates a Bytes without actually slicing and sharing them, it avoids the Shared
allocation entirely.
It's a lie
Let's step back a bit: the behavior above only happens when we create a Bytes from a Box<[u8]> or "full" Vec<u8>.
When we start with a non-full Vec<u8>, the code will not use the deferred mechanism and instead allocates a Shared
struct right away. In this case, there's no tagging of the data field and a dedicated vtable is used that will not
check for the tag:
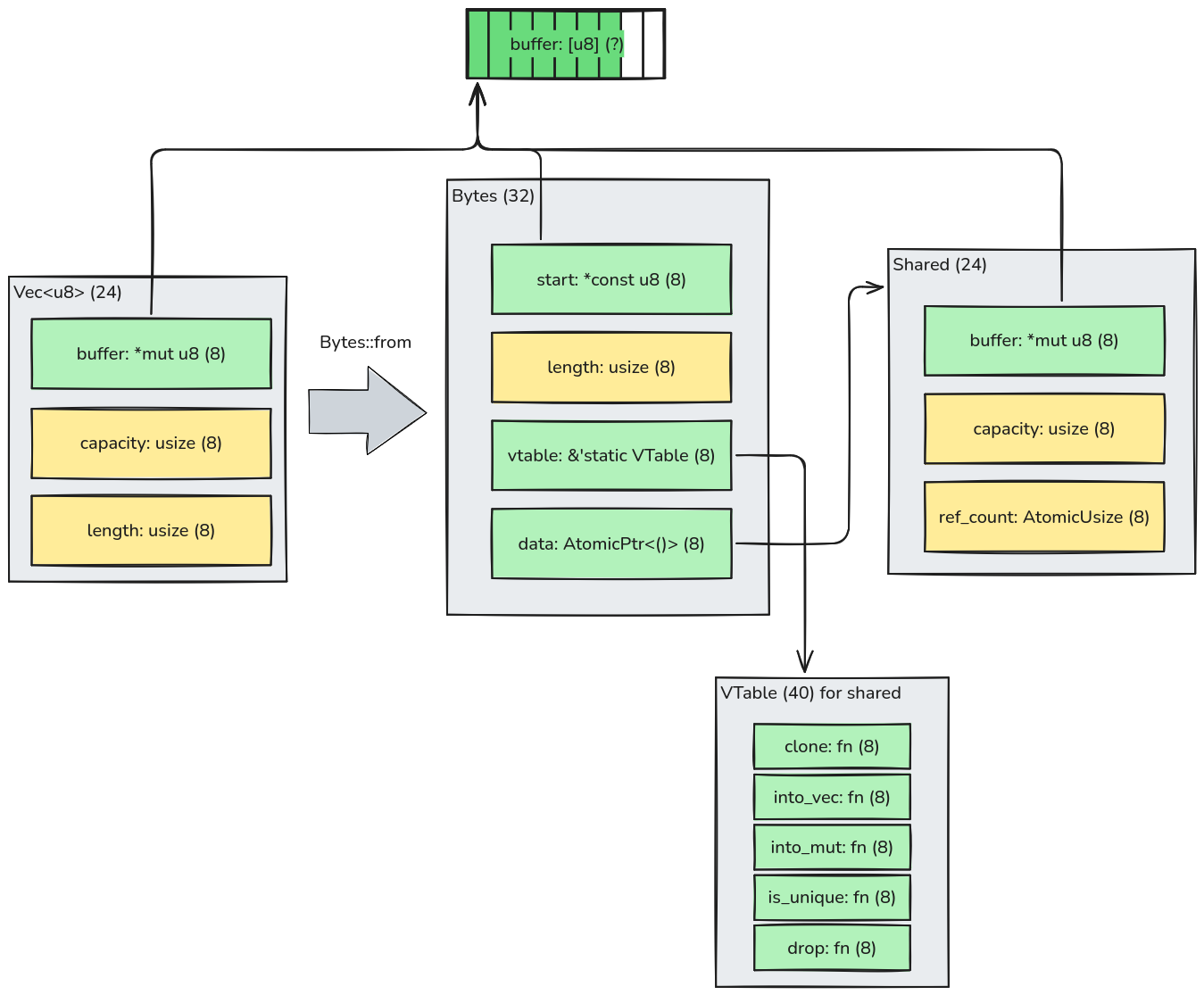
This is very similar to how the simpler SharedBytes work, except that Bytes has 8 more bytes for the vtable and
Shared has 8 fewer bytes than Arc<Vec<u8>> for the lack of weak references.
Bytes are versatile
The dynamic dispatch implemented by Bytes with the vtable and data fields effectively allows it to use custom
implementation for different backing storages of the data.
We saw what happens to Box and Vec. Here's what happens when you create a Bytes from an existing statically
allocated slice of bytes (in Rust represented as &'static [u8]):
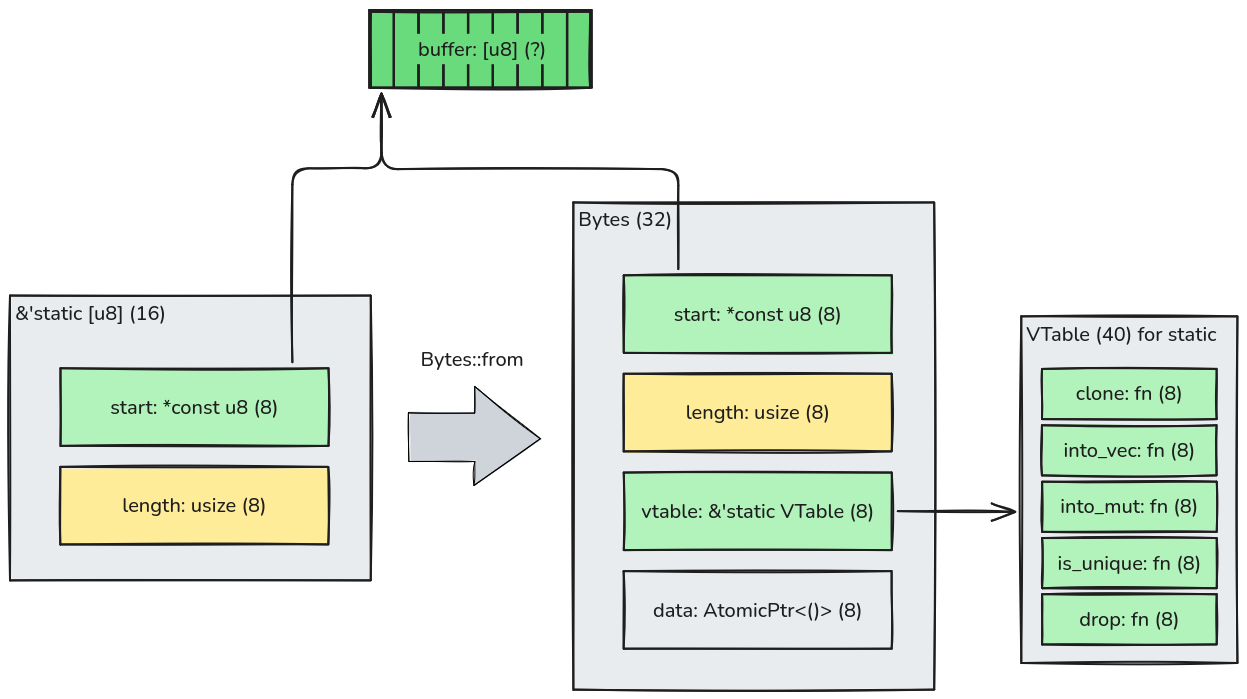
Note that there is no reference counting, because in this mode, Bytes does not own the data: instead it borrows data
that outlives it, as indicated by the 'static lifetime.
Another interesting usage of the dynamic dispatch is to create Bytes from anything else that somehow owns a buffer.
For example, from a memmap2::Mmap instance that represents a memory-mapped region:
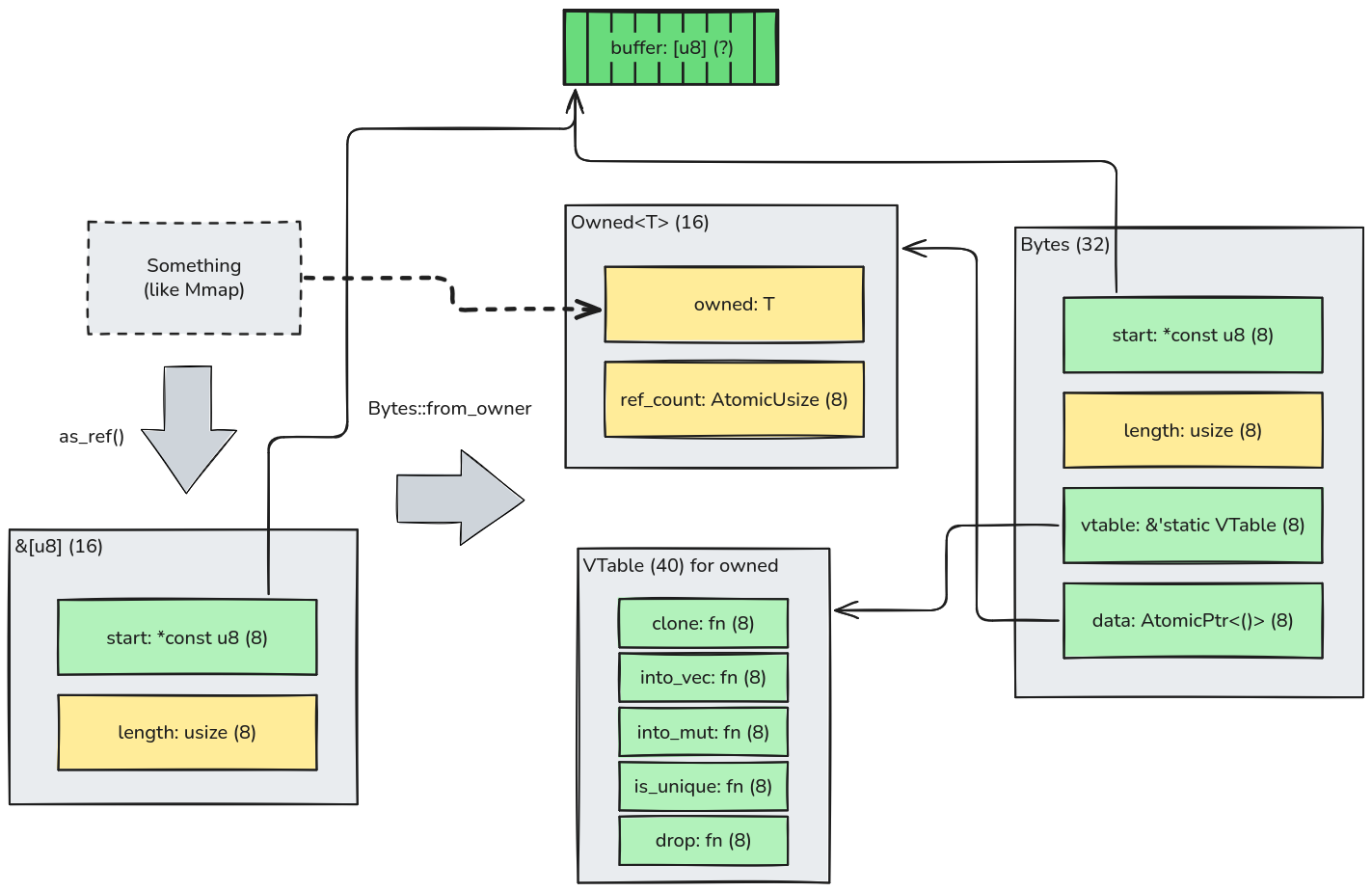
Note that the owned struct is copied over into Onwed that, just like Shared, acts like an Arc<_> without the weak
reference feature. The major distinction between Owned and Shared is that Bytes does not know how to take
ownership of the buffer, as it only requires that the given type implements AsRef<[u8]> to produces a
borrowed slice of bytes.
Micro benchmarks
Never trust a benchmark you see online. So here's one more for you to ignore:
fn test<B: BytesStorage>() {
let data = black_box(example_request_package());
let request = parse_request::<B>(data);
assert_example_request(&request);
}
Vec<u8> |
SharedBytes |
bytes::Bytes |
|
|---|---|---|---|
| Allocated (bytes) | 298 | 232 | 280 |
| Execution time (ns) | 115 | 115 | 150 |
So Bytes seems both chunkier and slower than my half-backed SharedBytes on this synthetic benchmark 🫣. But of
course, my implementation does not offer the same versatility.
I searched for public benchmarks that justified some design decisions on the bytes crate, but could not find them. If
you know any, please tell me!
Claire at 2026-03-03 21:58 UTC
C'est simple comme bonjour finalement
answer