This is my last week on my current job, and I was reflecting about some of the things that I've learned in the past 7 years there. There's a lot of course! As a staff data engineer, I worked with many teams and codebases and learned a couple of tricks at scale. So I'm starting a new blog series "performance advice nugget" (or PAN for short), in which I'll share some insights of what worked quite well in practice.
So welcome to PAN 01: use flat representations.
I'll try to make these posts quite short. As usual with everything related to "performance", you should always measure and benchmark with your real workload, and always balance whether additional complexity is worth the performance gains.
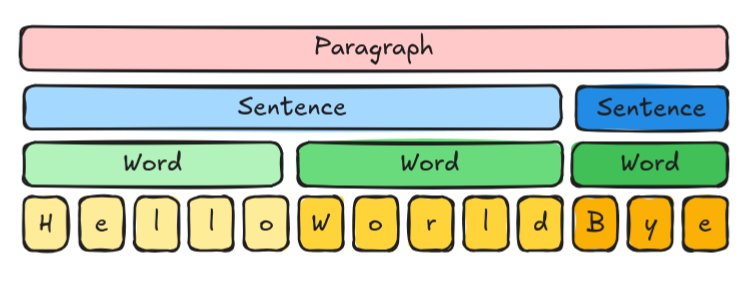
Nice, forewords are said and out of the way. Let's focus on the matter: imagine that you are handling a data that has multiple levels, for example, a paragraph, that is made of sentences, each made of words, each made of characters: