I like bytes, they're handy! I also like laying them in the right way to make things work and work fast. It turns out
I'm far from the only byte-nerd out there :)
In this post I'll dive deep into how Prometheus, an open source metrics and monitoring
service, represents time series information on the disk. To write this post, I've
read Prometheus' implementation,
played around with real data and also read
this series of posts by Ganesh Vernekar.
My goal is not to provide full documentation, instead I want to explore and learn with others' designs. I'll also
speculate why some things are the way they are and compare trade-offs with other alternatives I know.
This is the first post of a two-post series. The second installment will come soon, stay tuned with the RSS feed or the
newsletter!
Automated backups that work are mind-liberating! I've shared
in the previous post how I back up my data. In this post
I'll explore in detail how I handle encryption to protect my server and the insuing backup disks.
What does my system solve?
My encryption usage is meant to protect mostly against this threat:
if a stranger has access to any of my disks while they are unenergised, they must not be able to access my data.
For the backup disks this is rather simple to achieve by using full disk encryption
with Linux Unified Key Setup (LUKS).
Automated backups that work are mind-liberating! I'll share in this and the next post how I've solved it for my use case
in my homelab.
In this first post I want to explain my goals and my overall setup.
In the next post I'll explore in detail how I
handle encryption. I'd also love to hear how you handle your backups: share in the comments.
What does my system solve?
I like to think of my backup system in terms of the thread model against
the chaos and karma of the world. Which kinds of problems do I want to be protected against? After showering a couple of
times, I informally had a list on my head. Here it is, transcribed:
if I do something dumb, like deleting all my photos by accident, I want to recover that data (true story: when
migrating from Google Photos to Nextcloud, I've removed the wrong folder 😇).
if my machine breaks, I want to recover my data
if my house catches fire, is looted, or transforms itself into a pumpking (not true story), I want to recover my
data
if a stranger has access to any of the disks, they must not be able to access my data
if ransomware compromises my server, they cannot erase my backups
if I'm not available or just lazy, the system should mostly continue to work
if the system has problems, I should be notified
if the system silently stops running, I should notice
if in-disk data is inconsistent while the owner app is running, it must be stopped to flush the data
if a copied file gets corrupted or rots, it should be identified
if the writing patterns on the disks are similar, they should not fail at the same time due to correlated wear
and tear
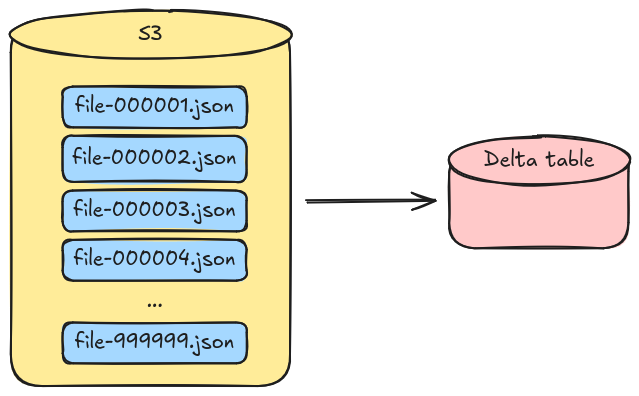
In the past, I've worked with a system that produced hundreds of thousands of compressed JSON files every day, each
weighting around 1MiB uncompressed. We wanted to ingest all that data into datalake for debug and analytics, and for
that we've used Spark to append to a delta table. Conceptually, the flow is very straight forward:
a job runs every day
it lists the new files that need to be ingested
those files are read
they are decompressed, parsed and encoded as parquet
these new parquet files are written to the table
In my last blog post,
I've dissected the delta table format and
showed
that it's basically just a bunch of JSON and parquet files. Part of that knowledge will be useful for this post, so
go take a look there if you want. I'll wait here :)
At its core, the Spark script to do this ETL is (in Python):
I'm coming back home from Rust Week 2026 in Utrecht 🦀. It was two days of interesting and
thought-provoking talks, followed by one day of coding together on Rust-related themes.
The venue was intelligently chosen: a cinema! No meet up can beat these comfortable human holders:
Talking to the sponsors, they use Rust for all sorts of projects, like developing microchips (Espressif), self-hosted
clouds (0xide), a platform for EV chargers in Holland (TandemDrive), data analysis (Polars), GPUs (Vectorware),
networking infrastructure (NLNetLabs), and editor (Zed).
I felt shy around the big crowd (I'm working on it...), but I was happy with myself because I've managed to discuss a
little with people in different moments of their Rust journey.
Today I'll share some points that I've learned while playing with Spark, Parquet and the Delta format. Even if you don't
use these technologies, I hope you can spot some neat ideas to reuse somewhere else later.
I like to picture in my head that the most important architectural distinction between a datalake table and a typical
database (like Postgres) is that compute and storage are handled very separately: the table's data is stored in one
distributed system (typically a cloud object storage), while another distributed system (or even multiple ones) read and
write to those files that compose the table.
There are competing formats to represent these tables, with distinct trade-offs of course: Delta, Iceberg, Hudi. But
from my research, I don't think there
is anything fundamentally different between then. This post
will focus on Delta, but most of it should be easily transposable for the others.
I like to understand technical solutions by framing the fundamental problems that they aim to solve best, so I'll
present it like that. Just remember that, although I have read
the specification and
have used Spark with Delta tables for years, I didn't invent any of this: I'm just an outside observer who
can be wrong. If you spot a misconception, please tell me in the comments!
This is my last week on my current job, and I was reflecting about some of the things that I've learned in the past 7
years there. There's a lot of course! As a staff data engineer, I worked with many teams and codebases and learned a
couple of tricks at scale. So I'm starting a new blog series "performance advice nugget" (or PAN for short), in which
I'll share some insights of what worked quite well in practice.
So welcome to PAN 01: use flat representations.
I'll try to make these posts quite short. As usual with everything related to "performance", you should
always measure and benchmark with your real workload, and always balance whether additional complexity is worth the
performance gains.
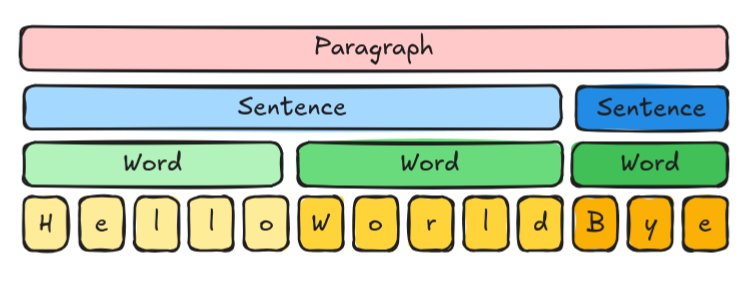
Nice, forewords are said and out of the way. Let's focus on the matter: imagine that you are handling a data that has
multiple levels, for example, a paragraph, that is made of sentences, each made of words, each made of characters:
In Rust, the tokio's ecosystem has a fundamental crate called bytes that abstracts
and helps dealing with bytes (you don't say!). I've indirectly used it a billion times and I thought that I had a good
mental model of how it worked.
So, in the spirit of the "decrusting" series
by the excellent Jon Gjengset, I've decided to peek behind the curtains to understand more what axum, tokio, hyper and
the kind do to them bytes! The code is well written, but surprisingly complex. I understand now what it does, but I
still don't fully grasp why it does some things in a certain way.
I'm ready to share with you my discoveries. I hope that you are sitting, laying or squatting comfortably. This is the
first post in a small series. I'm legally required by my marketing department to remind you that you can subscribe to
my low-traffic newsletter, so that you'll know when new posts are up!
A quick note before we start: this posts is based on the current bytes version 1.11.1.
This blog is written in Rust, and I wanted a way to reload the web pages automatically while I change the posts'
contents, styles, etc. This is common-place with JavaScript frameworks, but not automatic in the Rust land. So I've
embarked on a side quest to achieve just that: the "type and auto-reload" experience. In the end, I was surprised to
learn a bit more about sockets and processes in Linux.
This post is a note to myself about these nuggets that I've learned and to share the solution. It may be helpful for
future me and I hope for someonelse out there.