

In the past, I've worked with a system that produced hundreds of thousands of compressed JSON files every day, each weighting around 1MiB uncompressed. We wanted to ingest all that data into datalake for debug and analytics, and for that we've used Spark to append to a delta table. Conceptually, the flow is very straight forward:
- a job runs every day
- it lists the new files that need to be ingested
- those files are read
- they are decompressed, parsed and encoded as parquet
- these new parquet files are written to the table
In my last blog post, I've dissected the delta table format and showed that it's basically just a bunch of JSON and parquet files. Part of that knowledge will be useful for this post, so go take a look there if you want. I'll wait here :)
At its core, the Spark script to do this ETL is (in Python):
(
spark
.read
.option("pathGlobFilter", "*.json.zst")
.json(f's3a://bucket-name/service-name/date=2026-05-16/', schema=get_schema())
.write
.mode("append")
.format("delta")
.saveAsTable('table-name')
)
This instructs Spark to ingest all files in the S3 bucket "bucket-name" at the prefix "service-name/date=2026-05-16/" and ending in ".json.zst". The ".zst" extension signals to Spark that these files are compressed with z-standard.
The get_schema() function is important to tell Spark exactly the name and types of the fields. Without this, Spark
will auto-detect the schema, which is both slow (Spark needs to scan the files twice) and fragile (Spark cannot
guess all fields correctly all the time).
And it works! End of post, thanks.
... or is it ... ?
To have it run in an acceptable time (around 1 hour), we had to use a Spark cluster with more than 10 machines, each with 4 cores, 32 GiB and 1 TiB local SSD. We were using Databricks, so on top of the machine cost, we also paid their markup. All this to produce ~10 GiB of compressed data.
Sometimes we get our heads stuck in the clouds for too long and forget how crazy that should sound! For a totally non-scientific reference, I've searched for some rule-of-thumb speed for consumer hardware for the different tasks involved in the ingestion. Then I did some napkin math for the time to handle 10 GiB of compressed (100 GiB of uncompressed) data sequentially in a single thread:
| Task | Speed | Time |
|---|---|---|
| Download | 100 MiB/s | 100 s |
| Decompress zstd | 1000 MiB/s | 100 s |
| Parse JSON | 200 MiB/s | 500 s |
| Encode parquet | 50 MiB/s | 2 000 s |
| SSD write | 500 MiB/s | 20 s |
| Upload | 100 MiB/s | 100 s |
This adds up to a total of 47 minutes in a single-thread consumer hardware. Using more threads and concurrently running the IO-bound steps (like download, SSD write and upload) concurrently with CPU-bound steps, we should observe much better performance.
With the knowledge of how delta tables are organised internally as just a bunch of parquet files with the actual data and some JSON metadata for check pointing the versions, I got interested how it could be simpler.
Alternative approach
Instead of a Spark cluster, we can write a more focused program that reads, converts and writes the data. And for that, we can use the Rust and these crates to handle each one of the steps:
- tokio: run tasks concurrently and in-parallel
- aws-sdk-s3: list, download and upload files to S3
- zstd: decompress zstd
- arrow-json: re-encode json into arrow
- parquet: re-encode arrow into parquet
- deltalake: commit the changes to delta lake
- flume: implement multi-producer multi-consumer channels to handle inter-task communication
We can use a model of "pipelining", in which the whole operation is divided into tasks that can run in parallel, with bounded message channels connecting them:
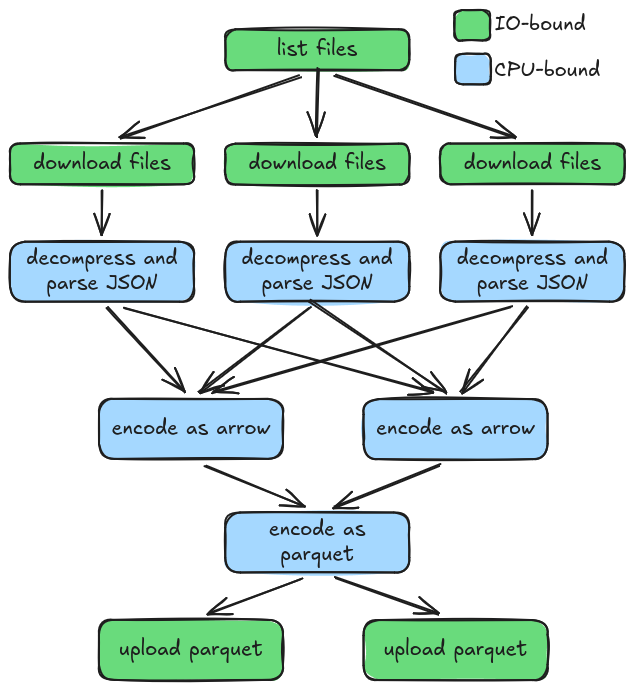
- list files: uses
aws-sdk-s3to go over the listing pages of a given prefix, generating the name asStringof the files to download - download files: uses
aws-sdk-s3to download the files into memory asBytes. Note that in this model, I'm assuming that each file is small enough to fully fit in memory. - decompress and parse JSON: uses
zstdandarrow-jsonto produce aTapeDecoderwhich represents the parsed JSON content as a flat sequence of tokens. - encode as arrow: uses
arrow-jsonto batch someTapeDecoders together and produce aRecordsBatch, which is a in-memory columnar representation of the data. - encode as parquet: uses
parquetto encode theRecordsBatchas parquet row groups and write the results to disk - upload parquet: uses
ask-sdk-s3to upload the generated parquet files
Note the use of the arrow encoding as an intermediate between JSON and parquet. This is useful because JSON is row-oriented, while parquet is column-oriented. This "inversion" is done in-memory with the help of arrow.
You
can check the actual implementation in this repo.
I had to patch arrow-json and deltalake crates, so that they expose some internal logic, because their current
public implementation could not be used as building blocks for this custom pipeline.
Benchmarking and results
To benchmark, I've used 2 machines in the same local network:
- a simple S3-compatible server
- a client machine, 32 GB of RAM and AMD Ryzen 7 2700X with 16 cores. It executes the ingestion, either with:
- Spark and Python - see source
- Rust and the pipeline explained above - see source
I've decided to implement my own S3 service - see source, for fun (I like tries!), but also to have total visibility of what Spark was doing.
I've then generated 10 000 compressed JSON files, each containing about 1MiB of uncompressed data. The schema has around 40 fields and nested lists of objects.
When running Spark without any further configuration, it produced 313 small parquet files, which seems bad for future read performance. So I've explicitly set the number of shuffling partitions in Spark to 3 and 10. To have a fair comparison, I've set the equivalent parameter in the Rust implementation to produce the same number of parquet files.
3 generated parquet files
| Metric | Spark | Rust | Difference |
|---|---|---|---|
| Total duration | 83.0 s | 27.2 s | -67 % |
| Peak CPU usage | 55.9 % | 36.6 % | -35 % |
| Peak memory usage | 3.2 GiB | 4.6 GiB | +46 % |
These are the CPU, memory and network usage curves (captured with dstat) through time:
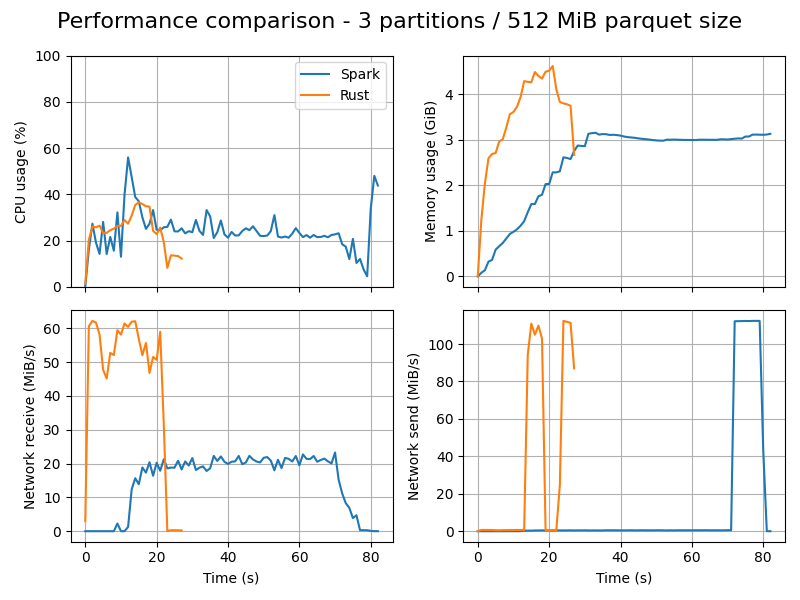
Spark has a fundamentally different architecture from the Rust implementation: each partition runs sequentially in a single core and does one thing at a time. You can imagine that each one of the 3 partitions runs independently and does one of these tasks:
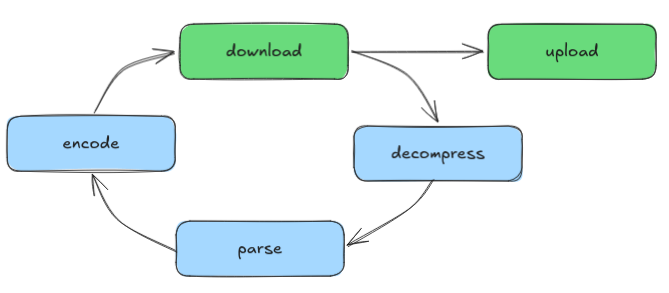
The problem with this architecture is that it always under-uses network and CPU: the network is idle while the CPU is working, and conversely, CPU is idle while the network is active. This drop is visible if we look at the "network receive" chart: note how Rust uses up to 60 MiB/s, while Spark stays at 20 MiB/s.
Another downside is that it ties the number of generated partitions with resource usage: to better use the machine resources, it's better to produce more parquet files. However, these extra files penalise the table read performance by future users.
10 generated parquet files
Let's look at the results with 10 partitions:
| Metric | Spark | Rust | Difference |
|---|---|---|---|
| Total duration | 53.3 s | 24.8 s | -54 % |
| Peak CPU usage | 86.2 % | 33.6 % | -61 % |
| Peak memory usage | 6.5 GiB | 2.9 GiB | -56 % |
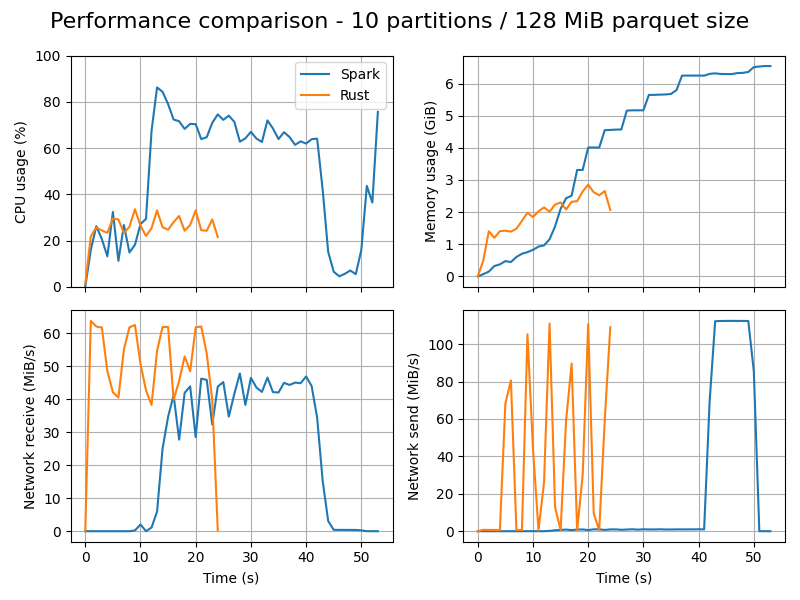
In Spark, more partitions lead to more effetive paralellism and usage of resources. Note how network receive goes up to near 50 MiB/s. The downside is that these independent tasks take more memory in total.
The Rust performance is clearly limited by the network: note how CPU usage is low while network receive and send fight each other.
Another fun fact is that when going from 3 to 10 generated parquet files, the peak memory usage of Spark increases (3.2 -> 6.5 GiB) while Rust's falls (4.6 -> 2.9 GiB). The reason makes sense when we compare the two distinct architecures: each Spark partition is independent and accumulates data in-memory: so more partitions, more usage. While Rust operates in terms of a pipeline with a target parquet size: so smaller parquet sizes will buffer less data in-memory.
Final words
I had a great time hacking together my own S3 service, tweaking Spark and using Rust's arrow, parquet and delta crates. The Rust datalake ecosystem is surprisingly mature and active.
I've tried for weeks to implement a JSON-to-parquet converter faster than arrow-json's, but I've failed! Which is
cool, their code is really interesting to read. But for this project, I've noticed that they could better support
parallel JSON parsing, which is something that I've implemented on my fork and hope to contribute upstream.
I'm also satisfied to validate my gut feeling that machines are quite fast and that Spark and Databricks were unnecessarily bloated for our use case.
Won't someone think of the bytes!
Leandro at 2026-06-14 00:40 UTC
Nice
answer
Thanks
answer