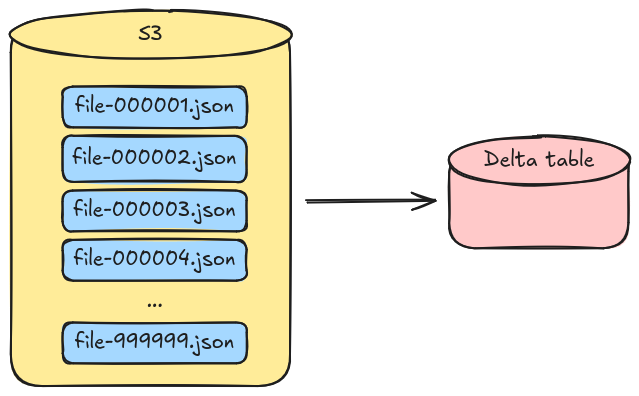
In the past, I've worked with a system that produced hundreds of thousands of compressed JSON files every day, each
weighting around 1MiB uncompressed. We wanted to ingest all that data into datalake for debug and analytics, and for
that we've used Spark to append to a delta table. Conceptually, the flow is very straight forward:
- a job runs every day
- it lists the new files that need to be ingested
- those files are read
- they are decompressed, parsed and encoded as parquet
- these new parquet files are written to the table
In my last blog post,
I've dissected the delta table format and
showed
that it's basically just a bunch of JSON and parquet files. Part of that knowledge will be useful for this post, so
go take a look there if you want. I'll wait here :)
At its core, the Spark script to do this ETL is (in Python):
... continue reading ...
Today I'll share some points that I've learned while playing with Spark, Parquet and the Delta format. Even if you don't
use these technologies, I hope you can spot some neat ideas to reuse somewhere else later.
I like to picture in my head that the most important architectural distinction between a datalake table and a typical
database (like Postgres) is that compute and storage are handled very separately: the table's data is stored in one
distributed system (typically a cloud object storage), while another distributed system (or even multiple ones) read and
write to those files that compose the table.
There are competing formats to represent these tables, with distinct trade-offs of course: Delta, Iceberg, Hudi. But
from my research, I don't think there
is anything fundamentally different between then. This post
will focus on Delta, but most of it should be easily transposable for the others.
I like to understand technical solutions by framing the fundamental problems that they aim to solve best, so I'll
present it like that. Just remember that, although I have read
the specification and
have used Spark with Delta tables for years, I didn't invent any of this: I'm just an outside observer who
can be wrong. If you spot a misconception, please tell me in the comments!
How it solves its main challenges
... continue reading ...

